
 For many years, universities have asked students to complete evaluations of teaching and other aspects of educational provision; since 2005 the UK government has conducted the National Student Survey to collect information from all students in UK Higher Education Institutions and the results are published annually. In this blog, I summarise some of my latest research on the reliability of student evaluations. Importantly I conclude that evaluations are informative about different aspects of teaching and can be used by staff as a diagnostic tool.
For many years, universities have asked students to complete evaluations of teaching and other aspects of educational provision; since 2005 the UK government has conducted the National Student Survey to collect information from all students in UK Higher Education Institutions and the results are published annually. In this blog, I summarise some of my latest research on the reliability of student evaluations. Importantly I conclude that evaluations are informative about different aspects of teaching and can be used by staff as a diagnostic tool.
Professor Edmund Cannon
Despite the potential for evaluations to be useful for teaching staff and university management, student evaluations of teaching (SETs) are controversial. The fundamental problem is that we rarely have an independent measure of teaching quality and are unsure how good students are at evaluating teaching. In other words: how do we evaluate the evaluators?
A big concern is the existence of evidence that students systematically give lower marks to female and ethnic-minority staff. There are also claims that staff may try to earn higher SET scores by lowering standards or inflating grades. One of my colleagues, Arnaud Philippe, writing with Anne Boring, shows that presenting evidence of gender bias to students before they complete an evaluation results in them changing their evaluations of male versus female staff, which suggests that student responses may be malleable.
Further reading: Reducing Discrimination in the Field: Evidence from an Awareness Raising Intervention Targeting Gender Biases in Student Evaluations of Teaching
These problems suggest that SETs may be unsuitable for comparison of different members of staff, because students’ responses could be due to other factors, such as student characteristics or psychological biases.
A more promising approach might be to use SETs as a diagnostic tool for staff to learn about their own strengths and weaknesses: this is possible because the same students evaluate a single member of staff teaching a single unit, but are asked about different aspects of the teaching: for example, is the teacher well organised, good at explaining things, producing good quality teaching material?
Together with my colleague Giam Pietro Cipriani, I have been addressing this question using data from an Italian university. Unlike the University of Bristol, completion of the SET is compulsory for students to be allowed to take the summative assessment, so there is a very high response rate.
We address two separate issues about the validity of SETs. First, do students on the same unit give similar scores to the same questions? If SETs are really measuring some underlying quality of the teacher, then there should be some agreement between students about the teacher’s strengths and weaknesses. The usual measure of agreement between raters (students) about different items (questions) is Cronbach’s alpha and we calculate this for all units for which we have data. A value of zero would mean that students perfectly disagreed over a member of staff’s strengths and weaknesses; a value of one would mean that students perfectly agreed over the strengths and weaknesses. Figure 1 shows the distribution of Cronbach’s alpha across different units: in most cases, the measure of agreement is high (between 0.75 and 0.95) and all of the instances where the alpha is low are on very small units where we should expect a lot of sampling error.
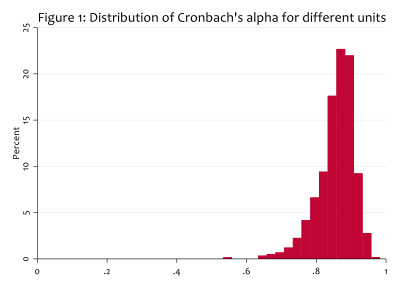
The fact that students largely agree with each other is a necessary but not a sufficient condition for their responses to be measuring some underlying qualities of the teacher. The questions on the evaluation ask students about things such as whether the teacher is well organised or whether the teacher explains things clearly. Do the answers to these different questions reliably inform us about organisation or quality of explanation?
It has long been hypothesised that student responses to different questions are too similar, a phenomenon known as the “halo effect”. For example, if a student likes a particular teacher, they might give that teacher a high score on every question, even in areas where the teacher is weak. If this effect is sufficiently large, the student gives the same numerical score to every question and the average response to each question is uninformative.
For each unit we analyse, Figure 2 reports a summary measure of how much each student gives the same answer to different questions (formally: the explanatory power of the first principal factor). This is different from Figure 1 which showed how much different students gave the same answer to each question. A value of zero means that students tend to answer each question differently, whereas a value of one means that students tend to answer each question the same. For most units, this measure is high, which is consistent with a halo effect, although it is possible that staff who are good at one aspect of teaching are typically good at other aspects of teaching too. From these data, we cannot distinguish the two possibilities.
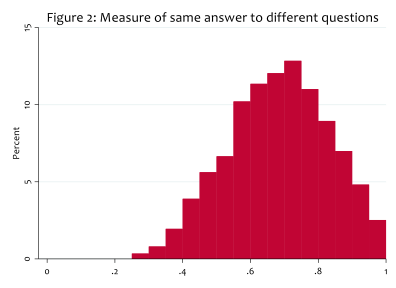
Our novel contribution is to use the fact that one question in the SETs we analyse is about the lecture room size, something which is uncorrelated with other aspects of teaching and over which teachers have no control. Importantly we know the actual lecture room seating capacity and so we are in the unusual position of being able to compare what the students say about the lecture room to an independent and objective measure. Figure 3 summarises one of our statistical analyses of this issue: almost a half (47 per cent) of the variation in students’ responses to the question on room size is explained by actual variation in room size. There is also some evidence for a halo effect since students’ responses about room size are influenced by their answers to other questions, but this explains a much smaller proportion of variation in SETs. A third of the variation in student responses is unexplained, but that is to be expected since there might be other aspects of lecture room size (such as layout) on which we do not have information.
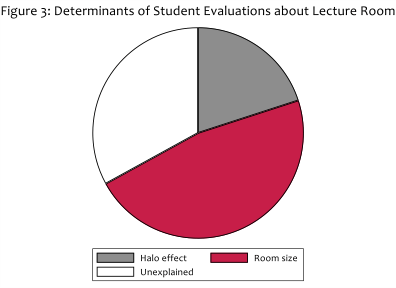
Our analysis shows that when independent information is available it correlates highly with students’ responses, suggesting that staff can use student evaluations as a diagnostic tool to help them improve their teaching. Despite a possible halo effect, responses to questions about different aspects of teaching are likely to be reliable. The important caveat is that our analysis does not say anything about whether evaluations of different staff members by different students can be used to make inter-staff (or inter-university) comparisons. Sadly, this is how evaluations are often used in practice.
The results in this blog are based on research published in Edmund Cannon & Giam Pietro Cipriani (2021) Quantifying halo effects in students’ evaluation of teaching, Assessment & Evaluation in Higher Education, DOI: 10.1080/02602938.2021.1888868